MMMU-Pro Needs an Update
MMMU-Pro1 has become a go-to public eval for frontier labs to showcase general vision capabilities. For example, it's one of the three multimodal evals Anthropic reports in the Claude Opus 4.6 system card2 and they summarize the dataset pretty concisely:
MMMU-Pro is a multimodal understanding benchmark that tests whether models can correctly perceive, interpret, and reason over college-level questions spanning diverse academic disciplines. MMMU-Pro improved on the original MMMU3 by filtering out text-only solvable questions, expanding multiple-choice options from four to ten, and introducing a vision-only input setting in which questions are embedded directly within images.

Frontier models have reported steady improvements in performance on MMMU-Pro. GPT-4o achieved 51.9% accuracy when the paper was published, but today Opus 4.6 gets 73.9%, GPT-5.2 has reached 79.5%, and Gemini 3 Pro hits 81.0%4.
But MMMU-Pro was created in 2024, which feels like a decade ago in terms of AI progress. Given its use as a headline multimodal eval by the labs and how much frontier capabilities have advanced in the past 18 months, it's worth revisiting how well the benchmark holds up and where current models succeed or fail.
Text-only frontier models are unreasonably effective
One of the main contributions of the benchmark was filtering out questions that could be solved with text-only. The authors describe this process with the following:
We begin by filtering out questions that can be answered by text-only LLMs. We select four strong open-source LLMs: Llama3-70B-Instruct, Qwen2-72B-Instruct, Yi-1.5-34B-Chat, and Mixtral-8x22B-Instruct and task them with answering the MMMU questions without access to images. The models are required to provide answers even when they indicate that visual input is necessary. We repeat this process ten times for each model, considering a question as “answerable” if a model correctly answers it more than five times. We then exclude any question where at least three out of the four models answer correctly across the majority of trials.
While those were strong open-source models for their day, they are now far behind the knowledge and reasoning capabilities of current models. It's likely then that there remain text-solvable questions that those models couldn't solve and thus weren't filtered out. Even by just looking at this figure from the paper we can see a sample that made it into the final dataset which is completely text-solvable:

Models today though are much more capable than the open-source models of 2024, so to test how the MMMU-Pro text-only filtering stands up to the current frontier models I ran Gemini 3 Pro, GPT-5.2 Thinking, and Claude Opus 4.6 on the Standard (10 options)5 version of the benchmark both with and without images6:
| Model | w/images | w/o images |
|---|---|---|
| Random Choice | 12.8 | 12.8 |
| Gemini 3 Pro | 82.5 | 48.7 |
| GPT-5.2 Thinking | 77.8 | 38.0 |
| Claude Opus 4.6 | 77.0 | 46.6 |
Even without images both Gemini 3 Pro and Opus 4.6 can answer nearly half of MMMU-Pro questions just through textual reasoning alone. I suspect this is possible due to superior reasoning abilities coupled with better world knowledge and recall of these current gen models.
MMMU-Pro does offer a Vision format where the image, question and choices are embedded in a screenshot or photo. I don't think this fully mitigates the text-only solvable questions, but merely enforces a minimum capability of OCR to solve these questions, i.e. if a model can at least read the text in the screenshot then it could ignore the rest of the image content and reason just from its text read-out.
An interesting example of how an unsuspecting question can be solved just with text is in the sample test_Diagnostics_and_Laboratory_Medicine_133. The question given to the model without the image looks like:
Which statement about the figure is correct?
A. These tumors are usually infrasellar
B. This tumor represent a metastasis from a lung carcinoma
C. They always present with endocrine deficiencies
D. This tumor represents a metastasis from a breast carcinoma
E. These tumors are usually suprasellar
F. They never present with endocrine deficiencies
One might think that this can only be answered if the image is given, yet all 3 models solved this question with only text. Opus's output shows how these models can combine their reasoning and knowledge to cleverly deduce the answer just from the options of the question:
Analyzing the Sellar Region Tumor
Step-by-step reasoning:
Key anatomical clue: The options reference "infrasellar" and "suprasellar," pointing to a tumor near the sella turcica (pituitary region).
Ruling out metastases: Options B (lung carcinoma metastasis) and D (breast carcinoma metastasis) can be eliminated — metastases to the sellar region are rare, and the question format suggests a primary tumor.
Endocrine presentation:
- Option C ("always present with endocrine deficiencies") is too absolute — many sellar region tumors present with visual symptoms (bitemporal hemianopia) or headaches rather than endocrine issues.
- Option F ("never present with endocrine deficiencies") is also too absolute and incorrect.
Location: This question most likely depicts a craniopharyngioma, which is:
- A benign tumor derived from Rathke's pouch remnants
- Characteristically suprasellar in location
- Can compress the optic chiasm and pituitary stalk
- May or may not cause endocrine dysfunction
Infrasellar vs. suprasellar: Craniopharyngiomas are classically suprasellar, making option A incorrect and option E correct.
Answer: E
Given that so many questions are still text answerable, what happens to these models' performance if we filter those questions out? We can adopt a similar criterion7 as the MMMU-Pro paper by removing questions where at least 2 of the 3 frontier models answer correctly without the image8. This results in 43% of questions being removed. We can view the most and least impacted subjects (view full table in Appendix):
| Subject | Total | Removed | Kept | % Removed |
|---|---|---|---|---|
| Literature | 52 | 39 | 13 | 75% |
| Electronics | 60 | 43 | 17 | 72% |
| Energy and Power | 58 | 39 | 19 | 67% |
| Math | 60 | 37 | 23 | 62% |
| Sociology | 54 | 30 | 24 | 56% |
| - | - | - | - | - |
| Basic Medical Science | 52 | 15 | 37 | 29% |
| Chemistry | 60 | 16 | 44 | 27% |
| Biology | 59 | 12 | 47 | 20% |
| Art | 53 | 9 | 44 | 17% |
| Music | 60 | 9 | 51 | 15% |
| TOTAL | 1730 | 736 | 994 | 43% |
The subjects with the least amount of image-dependent questions are Literature, Electronics, and Energy and Power while the subjects with the most image-dependent questions are Music, Art, and Biology. This "vision-required" subset is more difficult, the average frontier model performance drops about 10 percentage points compared to the full dataset (view full accuracy delta table in Appendix):
| Model | Full (1730) | Vision-Required (994) | Delta |
|---|---|---|---|
| Gemini 3 Pro | 82.5 | 73.8 | -8.7 |
| GPT-5.2 Thinking | 77.8 | 68.4 | -9.4 |
| Claude Opus 4.6 | 77.0 | 65.3 | -11.7 |
Furthermore, we can stratify performance by subject (sorted by average, view full table in Appendix):
| Subject | Gemini 3 Pro | GPT-5.2 Thinking | Claude Opus 4.6 |
|---|---|---|---|
| Finance | 93.1 | 96.6 | 96.6 |
| Electronics | 94.1 | 88.2 | 88.2 |
| Accounting | 86.5 | 89.2 | 89.2 |
| Marketing | 88.9 | 85.2 | 88.9 |
| Public Health | 90.2 | 87.8 | 80.5 |
| - | - | - | - |
| Mechanical Engineering | 58.6 | 51.7 | 41.4 |
| Agriculture | 45.7 | 42.9 | 37.1 |
| Literature | 46.2 | 46.2 | 30.8 |
| Music | 43.1 | 35.3 | 33.3 |
| Diagnostics and Laboratory Medicine | 23.7 | 31.6 | 21.1 |
| OVERALL | 73.8 | 68.4 | 65.3 |
All the models excel at visual tasks like Finance, Electronics, and Accounting, but are all quite bad at subjects like Literature, Music, and Diagnostics and Laboratory Medicine. Notably, those top 5 subjects are similar to each other in distribution of image types but are quite different from the bottom 5 subjects (view full table in Appendix):
| Subject | N | |||
|---|---|---|---|---|
| Finance | 29 | Tables (93%) | Plots and Charts (7%) | — |
| Electronics | 17 | Diagrams (94%) | Geometric Shapes (6%) | — |
| Accounting | 37 | Tables (97%) | Diagrams (3%) | — |
| Marketing | 27 | Tables (67%) | Plots and Charts (22%) | Diagrams (11%) |
| Public Health | 41 | Tables (83%) | Diagrams (10%) | Plots and Charts (7%) |
| - | - | - | - | - |
| Mechanical Engineering | 29 | Diagrams (69%) | Technical Blueprints (21%) | Geometric Shapes (7%) |
| Agriculture | 35 | Photographs (97%) | Microscopic Images (3%) | — |
| Literature | 13 | Photographs (46%) | Paintings (38%) | Comics and Cartoons (15%) |
| Music | 51 | Sheet Music (100%) | — | — |
| Diagnostics and Laboratory Medicine | 38 | Pathological Images (53%) | Microscopic Images (34%) | Medical Images (21%) |
I don't find this too surprising for a couple reasons. Subjects like finance, accounting, and marketing are all very economically valuable tasks and being good at visual reasoning on images of tables, plots, charts, and diagrams seems like low risk high reward capability to optimize for. It's probably also easier to optimize for relative to most other image types. High quality tables, plots, charts, and diagrams are plentiful on the web, academic papers, books, etc. They can also be easily generated synthetically, i.e. a strong LLM could create tables, plots, charts, and diagrams using markdown, LaTeX, HTML, etc. (and create auxiliary data as well, like question-answer pairs about the content) which could then be rendered as images and used in vision encoder and VLM training.
These types of images could also be easier to visually reason about relative to less structured images. For example, on images of tables, the model just needs to have strong OCR skills and 2D spatial understanding, enough to read off the data accurately and reconstruct it in text. Once that's done the model can basically discard the image and do the rest of its reasoning in text alone.
Frontier models can't read music
What is slightly surprising then is how poorly the models perform on sheet music. It doesn't seem too far away from the image distribution of tables, plots, charts, and diagrams to explain the drop in performance. After all, if a model had strong enough OCR-like ability to read the musical notation plus 2D spatial understanding it could convert the sheet music to a text-only format and do the rest of its reasoning in text as well. So why are they failing? Do they struggle with reading the music or just lack sufficient music theory knowledge and reasoning?
After looking through the music questions and models' answers, the common failure mode is that the models fail to read the notes and notation with consistent enough accuracy. When the models attempt to explicitly say what notes or notation they see, they often make obvious mistakes ~84% of the time on average9.
| Model | Misread | Attempted | Error Rate |
|---|---|---|---|
| Gemini 3 Pro | 44 | 52 | 85% |
| GPT-5.2 Thinking | 39 | 46 | 85% |
| Claude Opus 4.6 | 36 | 44 | 82% |
Take validation_Music_22 for example. The question is:
Which of the following best describes the seventh chord in the above example?A. Major seventh in third inversion
B. Major/minor seventh in third inversion
C. Minor/major seventh in first inversion
D. Minor seventh in third inversion
E. Major seventh in first inversion
F. Dominant seventh in second inversion
G. Dominant seventh in first inversion
H. Major/minor seventh in second inversion
I. Minor seventh in second inversion
J. Diminished seventh in second inversion

All 3 models got this question wrong because they thought they saw just slightly different notes than what was really shown.

The original chord is a G major seventh in third inversion.
Gemini and Claude both transcribed the key signature correctly, but both incorrectly transcribed the notes as two variations of the same chord. From bottom note to top Gemini read E - G - A - C# and Claude read G - A - C# - E. Gemini and Claude both reasoned then that the chord must be an A dominant seventh chord (A7) which is also a major minor chord. Gemini then concluded it saw a second inversion of the A7 while Claude concluded it saw a third inversion of the A7. Had the image really shown a chord with notes E - G - A - C# then Gemini's reasoning would've been spot on, and same for Claude if the image really showed G - A - C# - E.
Similar story for GPT-5.2 as well except it misread the key signature, only seeing the F#, and then incorrectly transcribed the chord notes as F# - A - C - D, but the reasoning from there was accurate. It correctly identified that as a D dominant seventh chord (D7) in first inversion. So once again, had the image really shown F# - A - C - D then GPT-5.2 would've reasoned to the right answer.
This pattern of barely misreading some notes (usually off by just one or two staff positions) happens frequently which then sends the model down an unrecoverable route of misguided reasoning. This seems like a lack of finer precision in the 2D spatial understanding of the vision components of the models but without knowing any of the model details it's hard to tell if it's an architecture issue or simply a data issue. I imagine stronger real and synthetic data curation could improve this capability a lot, but since reading sheet music isn't nearly as economically valuable as say finance and accounting tasks, it's no surprise the models are lacking here.
Bad image quality makes some questions impossible
What about the hardest subject, Diagnostics and Laboratory Medicine? The best performing model on the vision-required subset of this subject only hits 31.6% accuracy. Why are these models failing so badly?
From the image type distribution table we can see that Pathological Images and Microscopic Images make up 84% of the images in Diagnostics and Laboratory Medicine which happens to be a modality I've worked with for most of my career. Looking at the questions in this subject reveals a lot of low resolution pathology images which is a red flag for the answerability of these questions.
Some brief background, pathology images are digital scans of microscope slides containing tissue samples. This tissue is usually from something like a biopsy or surgical excision that then needs to be examined at the morphological and cellular level by a pathologist in order to render a diagnosis (i.e. determining if a patient has cancer, the type of cancer, the grade of cancer, etc.). In pathology the various scales of the visual diagnostic features can vary greatly, from inspecting the size of cell nuclei to the arrangement of glandular structures, which requires extremely high resolution imagery to capture such features at the same fidelity of various microscope magnification levels.
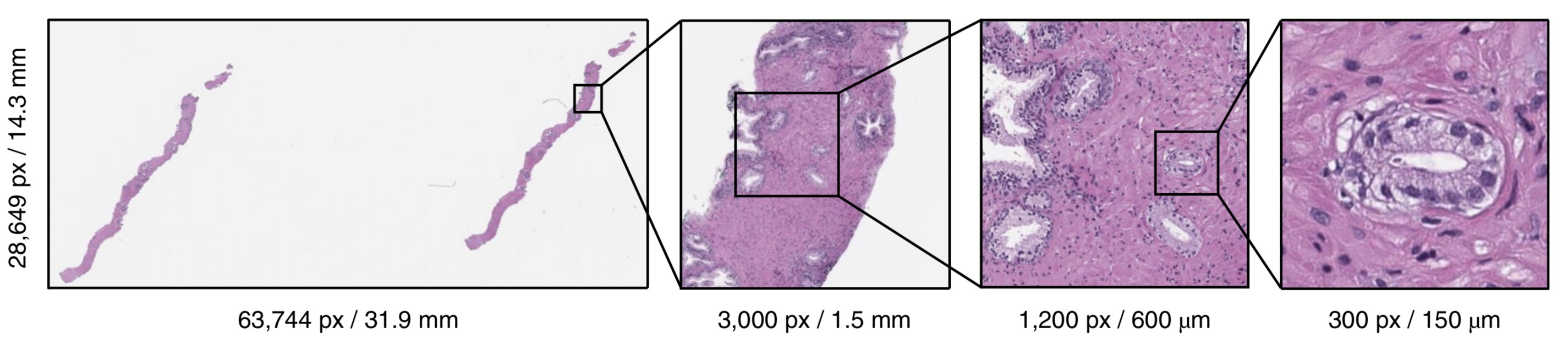
Above is a good illustration from Campanella et al.10 that shows a full resolution pathology image is of gigapixel scale (possibly even larger with higher resolution scanners nowadays, surpassing 100,000 x 100,000 px). However, the presence of cancer could occupy a region less than a 300 x 300 px. Many of the pathology images in MMMU-Pro try to capture an entire microscope slide in an image resized down to 1900 x 1600 px and sometimes even as low as 200 x 150 px in several questions. Clearly, even for larger scale diagnostic features, this resolution is likely to be completely unusable.
A prime example of this is validation_Diagnostics_and_Laboratory_Medicine_20:
45 year old Mexican rancher with 3 month history of cognitive problems. The most likely etiology of this process is:
A. Coccidiodal meningitis
B. Toxoplasmosis
C. Trypanosomiasis
D. Lyme disease
E. Tuberculosis meningitis
F. Amebic encephalitis
G. Cysticercosis
H. Cryptococcal meningitis
I. Herpes Simplex encephalitis
J. Meningococcal meningitis
The answer is coccidiodal meningitis, but all 3 models predict cysticercosis. To better understand this, fortunately some MMMU-Pro questions have expert explanations of the answers including this one:
This severe basilar meningitis is mediated by coccidioidomycosis. 20-40 micron diameter organisms are identified surrounded by an abundant inflammatory response.
The main takeaway from this explanation is that the discriminatory feature needed to answer this question is the 20-40 micron diameter coccidioides organism. I was able to find a full resolution version of this image via University of Pittsburgh's Department of Neuropathology11. Below I zoom into one of the coccidioides a model would need to detect:
In the image given to the model, which is about 1880 x 840 px, I was able to estimate that the tissue spans about a 45mm x 20mm physical area12. This would mean one pixel captures a ~24 micron square area. These 20-40 micron organisms then are essentially sub-pixel scale in the MMMU-Pro image, which shows this question clearly can't be answered by any model or human!
However, there are some questions in MMMU-Pro that use pathology images that are a zoomed-in crop of a region-of-interest where small diagnostic features become much more visible. Because of this, one hypothesis then is that the models should perform better on these higher magnification ROIs than the low magnification whole slide images.
To test that I manually went through all the questions in Diagnostics and Laboratory Medicine as well as Basic Medical Science and Clinical Medicine to identify all questions that had pathology images13 and I categorized them into two buckets of low magnification and high magnification and calculated the models' accuracy:
| Model | Low Magnification (N=19) | High Magnification (N=24) |
|---|---|---|
| Gemini 3 Pro | 5.3 | 54.2 |
| GPT-5.2 Thinking | 15.8 | 62.5 |
| Claude Opus 4.6 | 10.5 | 54.2 |
And indeed, what we see is the models are performing at around random chance on low magnification pathology images while performing significantly better on the high magnification ROIs.
Since the 19 questions with low magnification images are likely unanswerable due to these images and they make up half of the 38 questions in the vision-required subset of Diagnostics and Laboratory Medicine, this puts an upper bound of 50% accuracy in this subject (not accounting for correct random guessing).
Option augmentation increases label noise
Beyond text-only filtering, the other contribution of MMMU-Pro was to expand the number of candidate options of the original MMMU questions from 4 to 10. The authors describe their process for this with the following:
This augmentation is done by human experts with the help of GPT-4o, with additional validation steps to ensure the quality and diversity of the options. Specifically, GPT-4o generates and Claude 3.5 filters the options, followed by two rounds of human review to refine and verify the augmented options.
After sifting through many questions and model responses I noticed some instances of the new candidate options being just as correct as the ground truth answer or even invalidating the ground truth.
One example is validation_Pharmacy_24:
What is the following structure's <image 1> mechanism of action?
🔶 A. Alkylating agent
🟥 B. Chain terminator
✅ C. Topoisomerase poison
🔶 D. DNA crosslinker
🔶 E. RNA polymerase inhibitor
🔶 F. DNA gyrase inhibitor
🟥 G. Metallating agent
🔶 H. Reverse transcriptase inhibitor
🔶 I. DNA intercalator
🟥 J. Antisense agent
Annotations are added to illustrate the ground truth (✅), original distractors in the 4 options format (🟥) and additional distractors added by MMMU-Pro option augmentation (🔶).
All 3 models correctly identify this as the chemical structure of ciprofloxacin and they all select one of the new options, "F. DNA gyrase inhibitor", as their answers. The problem is that this new option happens to also be correct and is arguably a more specific description of ciprofloxacin's mechanism of action. When these new distractors aren't present by evaluating the models on the 4 options format, the models then align with the ground truth by selecting "C. Topoisomerase poison".
To try and quantify noise from option augmentation I flagged questions likely to be noisy based on a simple heuristic where all 3 models agree with each other on the same "wrong" answer. This surfaced 100 questions that I then reviewed which involved manually solving some questions, consulting online sources (i.e. solutions to textbook questions posted online), verifying the models' solutions, and when available cross checking the ground truth with explanations provided in the dataset. From this I found that 46 of these seem to have some sort of label noise, ~41% (19) of which could be attributed to noise from option augmentation.
Since the original augmentation process relied on the frontier models available at the time (GPT-4o, Claude 3.5 Sonnet), I suspect current generation models would perform more reliably creating high quality distractors. To test this, I used GPT-5.2 Thinking to re-do option augmentation from scratch for these 19 questions. Given a system prompt, image(s), question, and 4 original options, GPT-5.2 was asked to generate 6 additional options with guidelines to ensure the options were difficult but also not introducing non-mutually exclusive or overly ambiguous distractors (view system prompt in Appendix).
I then re-evaluated the models on these questions with the newly generated distractors:
| Model | 10 options | 4 options | Re-augmented 10 options |
|---|---|---|---|
| Gemini 3 Pro | 0.0 | 68.4 | 63.2 |
| GPT-5.2 Thinking | 0.0 | 73.7 | 47.4 |
| Claude Opus 4.6 | 0.0 | 63.2 | 57.9 |
By construction of how this subset of questions was selected, the performance is 0% on the original 10 option format, but we can see that the models recover most of their performance when evaluated on the 4 option format. The re-augmented options using GPT-5.2 appear to mitigate the original 10 option noise but still makes the questions harder than the 4 option format.
These 46 questions represent just a sample of the label noise in the dataset. 27 seem to be pre-existing issues from the original 4 option format and 19 introduced by option augmentation. That's a 70% increase in noise from the augmentation process in this subset.
Although it is a small sample of just 19 questions with option noise, it may be worth revisiting the augmentation process by using the stronger models that are available today for regenerating the additional candidate options across the full dataset.
Conclusion
MMMU-Pro was designed to test the perception, knowledge, and reasoning of multimodal models. But when the image(s) are withheld, current models can answer ~40% of the questions with just knowledge and reasoning alone.
By focusing on the remaining 60% of questions that require perception as well we can get a clearer assessment of model capabilities. The current frontier models show exceptional performance when dealing with tables, plots, and charts, but still struggle in areas like reading sheet music and medical imagery.
To some degree, noise also obscures true model performance. Image noise, like that of the low resolution pathology imagery, can make questions impossible to answer no matter how much models improve. And label noise present in the dataset, some of which is pre-existing and some from option augmentation, also silently penalizes models when they may be correct.
Two of these issues, text-only solvable questions and option augmentation noise, are artifacts of model capabilities in 2024 when the eval was created. The models available at the time that were used for these processes were not strong enough to filter all the text-solvable questions nor be free of error when creating additional options.
MMMU-Pro remains a useful benchmark for multimodal evals, but to maintain relevance it would benefit from re-filtering and re-augmenting options by utilizing the current generation of models.
Citation
@article{casson2026mmmuproupdate,
author={Adam Casson},
title={MMMU-Pro Needs an Update},
year={2026},
url={https://adamcasson.com/posts/mmmu-pro-update}
}A PDF version of this post can be found here (opens in a new tab).
Appendix
Per-subject text-only filtering table
| Subject | Total | Removed | Kept | % Removed |
|---|---|---|---|---|
| Literature | 52 | 39 | 13 | 75% |
| Electronics | 60 | 43 | 17 | 72% |
| Energy and Power | 58 | 39 | 19 | 67% |
| Math | 60 | 37 | 23 | 62% |
| Sociology | 54 | 30 | 24 | 56% |
| Marketing | 59 | 32 | 27 | 54% |
| History | 56 | 30 | 26 | 54% |
| Finance | 60 | 31 | 29 | 52% |
| Clinical Medicine | 59 | 30 | 29 | 51% |
| Mechanical Engineering | 59 | 30 | 29 | 51% |
| Physics | 60 | 30 | 30 | 50% |
| Economics | 59 | 27 | 32 | 46% |
| Pharmacy | 57 | 25 | 32 | 44% |
| Art_Theory | 55 | 24 | 31 | 44% |
| Agriculture | 60 | 25 | 35 | 42% |
| Psychology | 60 | 24 | 36 | 40% |
| Architecture and Engineering | 60 | 22 | 38 | 37% |
| Computer Science | 60 | 22 | 38 | 37% |
| Design | 60 | 22 | 38 | 37% |
| Diagnostics and Laboratory Medicine | 60 | 22 | 38 | 37% |
| Accounting | 58 | 21 | 37 | 36% |
| Materials | 60 | 21 | 39 | 35% |
| Geography | 52 | 17 | 35 | 33% |
| Manage | 50 | 15 | 35 | 30% |
| Public Health | 58 | 17 | 41 | 29% |
| Basic Medical Science | 52 | 15 | 37 | 29% |
| Chemistry | 60 | 16 | 44 | 27% |
| Biology | 59 | 12 | 47 | 20% |
| Art | 53 | 9 | 44 | 17% |
| Music | 60 | 9 | 51 | 15% |
| OVERALL | 1730 | 736 | 994 | 43% |
Per-subject accuracy delta between full dataset and "vision-required" subset
| Subject | Gemini 3 Pro | GPT-5.2 Thinking | Claude Opus 4.6 | Avg |
|---|---|---|---|---|
| Literature | -36.5 | -36.5 | -50.0 | -41.0 |
| Diagnostics and Laboratory Medicine | -26.3 | -16.8 | -25.6 | -22.9 |
| Agriculture | -19.3 | -18.8 | -19.5 | -19.2 |
| Mechanical Engineering | -17.7 | -17.8 | -21.3 | -18.9 |
| Clinical Medicine | -19.6 | -16.0 | -17.7 | -17.8 |
| Psychology | -11.7 | -13.9 | -20.0 | -15.2 |
| Energy and Power | -7.2 | -17.8 | -17.8 | -14.3 |
| Physics | -10.0 | -15.0 | -16.7 | -13.9 |
| Sociology | -11.1 | -13.0 | -17.6 | -13.9 |
| History | -12.6 | -8.4 | -18.8 | -13.3 |
| Math | -8.0 | -10.1 | -17.1 | -11.7 |
| Materials | -6.3 | -13.5 | -15.3 | -11.7 |
| Pharmacy | -12.3 | -11.6 | -8.8 | -10.9 |
| Manage | -9.4 | -10.0 | -12.0 | -10.5 |
| Economics | -6.9 | -6.9 | -8.6 | -7.5 |
| Marketing | -6.0 | -8.0 | -6.0 | -6.7 |
| Art Theory | -6.6 | -8.0 | -4.8 | -6.5 |
| Basic Medical Science | -3.5 | -4.0 | -9.8 | -5.8 |
| Architecture and Engineering | -5.1 | -5.1 | -5.8 | -5.3 |
| Computer Science | -5.1 | -2.7 | -8.2 | -5.3 |
| Geography | -2.7 | -2.6 | -9.3 | -4.9 |
| Chemistry | -3.6 | -3.8 | -6.7 | -4.7 |
| Biology | -1.4 | -5.6 | -6.9 | -4.6 |
| Electronics | -2.5 | -6.8 | -1.8 | -3.7 |
| Music | -5.2 | -1.4 | -3.3 | -3.3 |
| Public Health | -1.1 | -1.9 | -5.7 | -2.9 |
| Design | -1.8 | +1.6 | +0.4 | +0.1 |
| Finance | -0.2 | +1.6 | -0.1 | +0.4 |
| Accounting | +0.3 | +1.3 | +1.3 | +1.0 |
| Art | +0.3 | -0.9 | +4.8 | +1.4 |
| OVERALL | -8.7 | -9.4 | -11.7 | -9.9 |
Full per-subject vision-required accuracy table
| Subject | Gemini 3 Pro | GPT-5.2 Thinking | Claude Opus 4.6 |
|---|---|---|---|
| Finance | 93.1% | 96.6% | 96.6% |
| Electronics | 94.1% | 88.2% | 88.2% |
| Accounting | 86.5% | 89.2% | 89.2% |
| Marketing | 88.9% | 85.2% | 88.9% |
| Public Health | 90.2% | 87.8% | 80.5% |
| Art | 90.9% | 72.7% | 84.1% |
| Architecture and Engineering | 81.6% | 81.6% | 84.2% |
| Economics | 81.2% | 81.2% | 81.2% |
| Chemistry | 86.4% | 79.5% | 75.0% |
| Art_Theory | 80.6% | 77.4% | 80.6% |
| Design | 81.6% | 81.6% | 73.7% |
| Math | 87.0% | 78.3% | 69.6% |
| Computer Science | 81.6% | 78.9% | 68.4% |
| Geography | 85.7% | 68.6% | 71.4% |
| Energy and Power | 84.2% | 68.4% | 68.4% |
| Biology | 76.6% | 72.3% | 66.0% |
| Basic Medical Science | 81.1% | 73.0% | 59.5% |
| Pharmacy | 71.9% | 65.6% | 71.9% |
| Physics | 76.7% | 70.0% | 56.7% |
| Materials | 82.1% | 61.5% | 56.4% |
| History | 73.1% | 57.7% | 61.5% |
| Sociology | 66.7% | 66.7% | 58.3% |
| Manage | 68.6% | 60.0% | 60.0% |
| Psychology | 66.7% | 52.8% | 50.0% |
| Clinical Medicine | 44.8% | 58.6% | 58.6% |
| Mechanical Engineering | 58.6% | 51.7% | 41.4% |
| Agriculture | 45.7% | 42.9% | 37.1% |
| Literature | 46.2% | 46.2% | 30.8% |
| Music | 43.1% | 35.3% | 33.3% |
| Diagnostics and Laboratory Medicine | 23.7% | 31.6% | 21.1% |
| OVERALL (994) | 73.8% | 68.4% | 65.3% |
Full per-subject image type distribution table
| Subject | N | |||
|---|---|---|---|---|
| Finance | 29 | Tables (93%) | Plots and Charts (7%) | — |
| Electronics | 17 | Diagrams (94%) | Geometric Shapes (6%) | — |
| Accounting | 37 | Tables (97%) | Diagrams (3%) | — |
| Marketing | 27 | Tables (67%) | Plots and Charts (22%) | Diagrams (11%) |
| Public Health | 41 | Tables (83%) | Diagrams (10%) | Plots and Charts (7%) |
| Art | 44 | Paintings (80%) | Photographs (18%) | Portraits (7%) |
| Architecture and Engineering | 38 | Tables (58%) | Diagrams (37%) | Geometric Shapes (3%) |
| Economics | 32 | Tables (62%) | Plots and Charts (38%) | — |
| Chemistry | 44 | Chemical Structures (68%) | Plots and Charts (16%) | Tables (11%) |
| Art Theory | 31 | Paintings (48%) | Photographs (29%) | Sculpture (19%) |
| Design | 38 | Paintings (42%) | Photographs (26%) | Diagrams (11%) |
| Math | 23 | Diagrams (22%) | Plots and Charts (22%) | Tables (17%) |
| Computer Science | 38 | Diagrams (58%) | Trees and Graphs (24%) | Plots and Charts (8%) |
| Geography | 35 | Diagrams (34%) | Maps (34%) | Photographs (23%) |
| Energy and Power | 19 | Diagrams (79%) | Geometric Shapes (16%) | Technical Blueprints (5%) |
| Biology | 47 | Diagrams (30%) | Plots and Charts (15%) | Photographs (13%) |
| Basic Medical Science | 37 | Microscopic Images (24%) | Diagrams (24%) | Medical Images (19%) |
| Pharmacy | 32 | Chemical Structures (56%) | Plots and Charts (16%) | Tables (12%) |
| Physics | 30 | Diagrams (77%) | Plots and Charts (17%) | Geometric Shapes (10%) |
| Materials | 39 | Diagrams (72%) | Tables (5%) | Geometric Shapes (5%) |
| History | 26 | Comics and Cartoons (19%) | Tables (15%) | Maps (15%) |
| Sociology | 24 | Photographs (29%) | Diagrams (21%) | Comics and Cartoons (17%) |
| Manage | 35 | Tables (49%) | Diagrams (17%) | Plots and Charts (14%) |
| Psychology | 36 | Plots and Charts (47%) | Diagrams (25%) | Tables (14%) |
| Clinical Medicine | 29 | Body Scans (52%) | Medical Images (28%) | Pathological Images (17%) |
| Mechanical Engineering | 29 | Diagrams (69%) | Technical Blueprints (21%) | Geometric Shapes (7%) |
| Agriculture | 35 | Photographs (97%) | Microscopic Images (3%) | — |
| Literature | 13 | Photographs (46%) | Paintings (38%) | Comics and Cartoons (15%) |
| Music | 51 | Sheet Music (100%) | — | — |
| Diagnostics and Laboratory Medicine | 38 | Pathological Images (53%) | Microscopic Images (34%) | Medical Images (21%) |
Option re-augmentation system prompt
You will be given a question with image(s), its subject area, the existing answer options, and which option is correct. Your job is to generate new distractor options to bring the total to 10.
## Rules
1. **No new option may be correct or arguably correct.** The ground truth must remain the only right answer.
2. **No new option should contradict or invalidate the ground truth.** A test-taker who knows the material should still unambiguously pick the original correct answer.
3. **All new options must be plausible** in the context of the question and subject area — they should look like something a student who studied the material might consider.
4. **College-level difficulty.** Distractors should not be too easy and still be challenging, including options that are subtly wrong (e.g. a common misconception, an off-by-one value, a related-but-incorrect term).
5. **Match format, length, and style** of the existing options. If the originals are short numeric values, produce short numeric values. If they are full sentences, produce full sentences.
6. **No duplicates** of existing options or trivial rephrasings of them.
7. **For quantitative questions**, use numerically plausible values (nearby magnitudes, common calculation errors).
8. **For terminology questions**, use real terms from the same domain that a student might confuse with the correct answer.
## Output format
Respond with a single JSON object (no markdown fences):
{
"new_options": ["new option 1", "new option 2", ...],
"reasoning": "brief explanation of your distractor design choices"
}
The `new_options` array must contain exactly the number of new options requested. Do not include letter prefixes (A., B., etc.) — just the raw option text.Footnotes
-
Yue, X., Zheng, T., Ni, Y., Wang, Y., Zhang, K., Tong, S., Sun, Y., Yu, B., Zhang, G., Sun, H., Su, Y., Chen, W., Neubig, G. MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark (opens in a new tab). ACL 2025. 2025. ↩
-
Anthropic. System Card: Claude Opus 4.6 (opens in a new tab). 2026. ↩
-
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., Wei, C., Yu, B., Yuan, R., Sun, R., Yin, M., Zheng, B., Yang, Z., Liu, Y., Huang, W., Sun, H., Su, Y., Chen, W. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI (opens in a new tab). CVPR 2024. 2024. ↩
-
Since the time I ran these evals, Gemini 3 Deep Think was released with 81.5% accuracy. Gemini 3.1 Pro was released which has 80.5% accuracy (which is actually lower than Gemini 3 Pro). And GPT-5.4 Thinking (xhigh) was released with 81.2% accuracy. ↩
-
There are some discrepancies in the accuracies I report here and what the labs report. The standard way MMMU-Pro accuracy is calculated is by averaging model performance on the
Standard (10 options)andVisionformats (where question and choices are rendered into a composite image along with the original image). Here I only run the models once on theStandard (10 options)format. ↩ -
Gemini 3 Pro evals used
gemini-3-pro-previewwith thinking level ofhigh. GPT-5.2 Thinking evals usedgpt-5.2-2025-12-11with reasoning effort ofhigh. Claude Opus 4.6 evals usedclaude-opus-4-6with thinking type ofadaptiveand effort ofhigh. TheCoTprompt from MMMU-Pro eval was used on all runs. ↩ -
MMMU-Pro's criteria is stricter as they do 10 runs per model and a question has to be answered correctly a majority of the time by 3/4 models to be filtered out. I wasn't able to do multiple runs per model because it gets pretty expensive just to run each model once. ↩
-
I also automatically keep questions that have images as answer options. Upon inspection, the text-only models hallucinate/guess the image contents and get lucky with picking the right option sometimes. ↩
-
This was calculated via manual inspection of all 60
Musicproblems. A misread for a model was noted if it tried to write down what notes/notation it saw in final responses (not thinking tokens/summaries) that included any errors. In some instances, a model could make obvious errors but still get a question correct, i.e. it misreads 2 notes that happen to have the same interval as the notes that the question is about. ↩ -
Campanella, G., Hanna, M.G., Geneslaw, L., Miraflor, A., Silva, V.W.K., Busam, K.J., Brogi, E., Reuter, V.E., Klimstra, D.S., Fuchs, T.J. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images (opens in a new tab). Nature Medicine. 2019. ↩
-
The case can be seen here (opens in a new tab) and the high resolution viewer of the image here (opens in a new tab). The image is not an exact copy, but is no doubt taken from the same block of tissue and is likely a scan of slightly different slice of that block. ↩
-
The full resolution image from UPitt is 62000 x 39359 px at 0.5 microns per pixel which converts to approximately 31mm x 20mm. The MMMU-Pro image is 1880 x 840 px (after cropping padding on the top and bottom). Since the UPitt copy is cropped horizontally compared to the MMMU-Pro version, we can use the vertical dimension to estimate the pixel area of MMMU-Pro image: 20000 microns per 840 px ≈ 24 microns per px. We can then use that to also estimate the physical width of the image: 1880 px * 24 microns per px ≈ 45mm. ↩
-
MMMU-Pro has
img_typelabels for each question but this was bit noisy for this purpose. ↩